Introduction
Puppet is a Ruby based Configuration Management System with client/server model, licensed under GPLv2 .It has one Master server puppetmasterd and all other machines are configured as puppet clients . We set configurations at the puppet server and then push them to all clients which are connected to the master. The client puppet correctly applies the corresponding configurations on the client machine regardless of their platform difference.
Puppet is a gift to the server administrators who need to manage a large number of systems with different flavor of Gnu/Linux, Mac, Solaris and other Unix Based systems.If we are managing systems via remote administration then it would be a headache to the administrator and if the systems are different then the complexity will increase. Some accidental configuration changes may cause inconsistent working of the server. If we are using the Puppet for the configuration management then it will be a one time implementation of these configuration changes only at puppet server, then we just apply them to different puppet clients without any delay.
Another power of the puppet is it uses a Declarative Language to define configuration settings at the puppet master server. This language includes all major high level language features like Functions, Conditional Statements, Inheritance and other OOPs concepts. This feature makes for more readable , reusable and consistent Puppet configurations settings, when we compared with other configuration management tools like Cfengine.
Working
Puppet master server stores all client configurations, and each client will contact the server via port 8140 (by default). The connection between server and client is encrypted. The client will generate a self-signed key before it connects to server and will submit this self-signed key to the master server and get the verified key back. Here master server acts like a Certification Authority. After this process, the client will establish a encrypted session with the server and get the configuration settings, then compile and apply it on client system. When the client compiles the configurations from server it may rise error messages if there are any syntax errors in the configuration definitions. We can verify this on the puppet server and client log file.
Here is the outline of puppet server and client Architecture
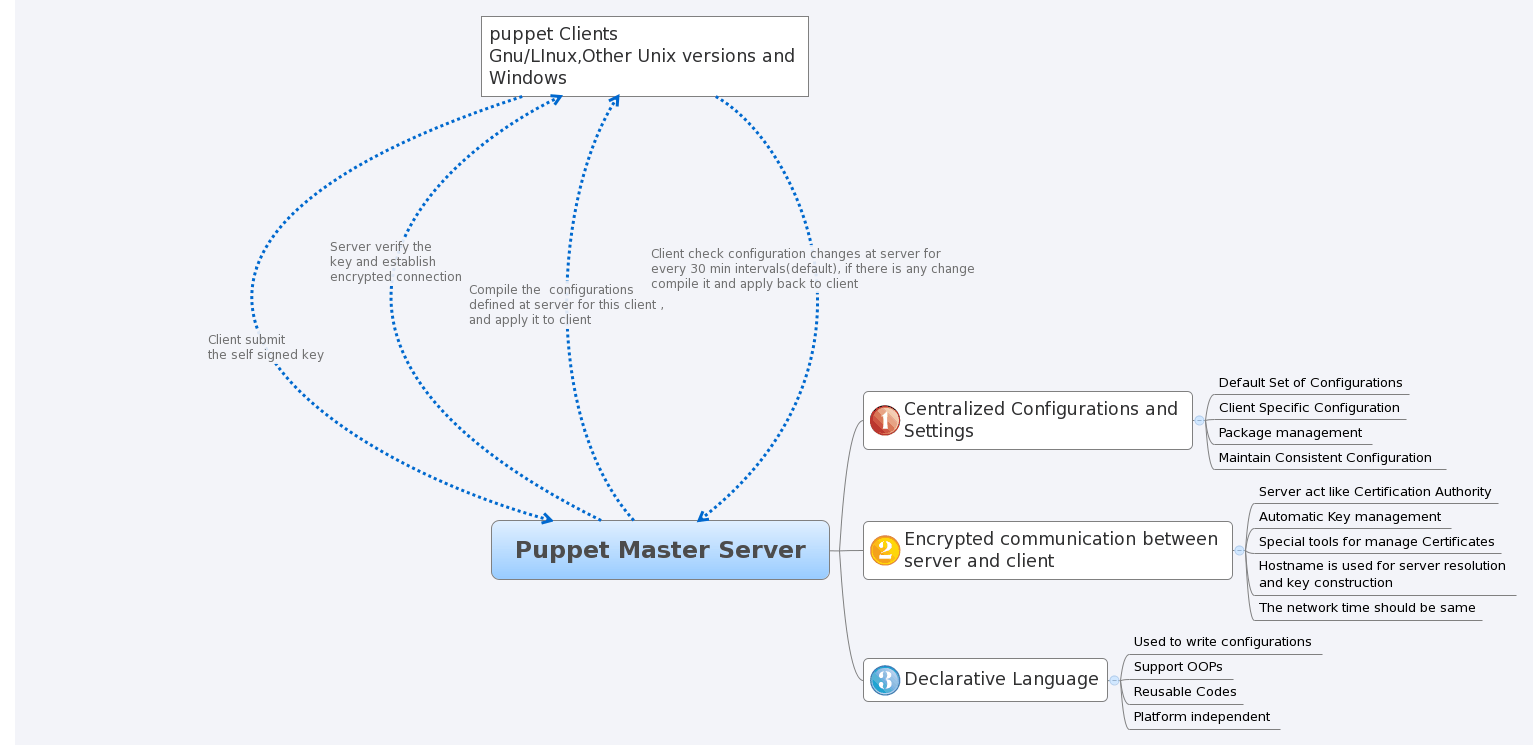
Puppet Architecture
Installation
Before installing Puppet, we need to setup some dependencies. First we need ruby with common library files(xml,ssl,etc.) installed, and facter, which is another ruby project that gathers all system information. Facter will be installed in all puppet clients. The puppet server retrieves the client configuration settings and other system-specific details from facter.
You can use the ruby’s built-in library management tool rubygem(rake) (similar to CPAN for Perl) to solve the dependency problems with libraries.
Facter installation :-
Get latest version from www.reductivelabs.com
1 |
tar -zvf facter-<version>.tar.gz |
Puppet installation :-
If we are installing from the package manager, there will be two packages: puppetd as the client and puppet-master as the Puppet server. We need to install both to setup the client and server, and both can be installed from the source code.
Download latest package from the www.puppetlabs.com, then similar to facter installation:
1 |
tar -xzvf puppet-<latest version>; |
3 |
cd puppet-<latest-version>; |
9 |
useradd -g puppet puppet |
This step will install the required packages for the Puppet client and server. If you have any dependency problems then it might be due to a version mismatch problem between ruby/puppet/facter, so select correct the versions.
By default, the configuration files are listed under /etc/puppet and all others are in the /var/lib/puppet folder (including log files).
Currently Puppet support all major Unix like systems but not Windows.The latest versions of the Puppet has introduced support for the Windows operating system by developing Windows specificfacter tool.
How to configure Puppet server :-
After successful installation of the Puppet master server and client, there is a set of daemons associate with this package as well as command line utilities to manage these daemons. They are:
Puppet work without creating configuration files explicitly; they are already pre-configured. But to start the interaction with clients we need to make some changes. First, we can check the structure of the puppet configuration file.
It’s a good practice maintaining an explicit puppet configuration file;the latest versions of puppet use single configuration file to manage every daemons. By default, configuration files are stored under /etc/puppet. We save all the configuration details of major daemons at /etc/puppet/puppet.conf.The puppet.conf use a special type of configuration structure to include every daemon’s configuration details,described below:
01 |
#Cat /etc/puppet/puppet.conf |
05 |
Here We specify a set of configuration details common to all daemons. |
09 |
Here comes the Puppet master server configuration details. |
13 |
To include the Puppet client configurations. |
17 |
Configuration details of puppet key management tool. |
To get all the parameters under each daemons and main section with its functional details, please refer this page
How to Connect Puppet Client with Puppet Server
To set up a client we just have to install the puppet client version or every package in another system.Your master server is now capable to work as a puppet client also. At the master server we need to specify the set of configuration that will guide how to change the configurations at clients.
Puppet server and client use Hostname to communicate with each other and also used to generate ssh key and key verification etc.., so we need a stable hostname resolution system (DNS or Local settings) in our network to ensure the proper connection between clients and server.So select proper hostnames to your server and clients like:
puppet-server.com #For your Master Server
puppet-client1.com,puppet-client2.com,etc... #Your clients.
After the hostname allocation we need to start the server and client daemons.Use command line options now to know the more about the interactions between client and server.
To start the master server :-
1 |
puppetmasterd --no-daemonize --logdest console |
Then Start the puppet Client, specify the server name
1 |
puppetd --server puppet-server.com --verbose --waitforcert 30 |
On the client side we will get the message regarding the creation of a self signed key and waiting for server verification.
1 |
Creating a new SSL key for puppet-client.com |
2 |
Creating a new SSL certificate request for puppet-client.com |
3 |
Certificate Request fingerprint (md5): 37:89:4E:86:C0:A7:5B:24:1A:E2:9B:85:83:90:0F:CE |
4 |
Did not receive certificate |
At the same time server side we will get the following message.
1 |
notice: Starting Puppet master version 2.6.0 |
2 |
notice: puppet-client.com has a waiting certificate request |
To proceed further , at server side we need to verify this key from the puppet-client.com. For that we can use the key management tool puppetca.
3 |
puppetca --sign puppet-client.com |
Now If we are restarting the puppet client with following command, you can see the client will immediately apply the configurations. You can check this from the log file or from the console if you are running the client in none daemonize mode.
1 |
puppetd --server puppet-server.com |
Note:- If we are specify these settings at puppet.conf then you can just type the commands without any parameters to start appropriate daemons.
The Configuration Management
Last and very powerful feature of the puppet is the way Puppet server define the Client configurations. For that Puppet use one declarative language which support most of the high level language constructs like OOPs. So lets try one simple configuration which change the permission of /etc/passwd file at all the clients connected with server to 640 and check Apache webserver installed or not , if not, puppet client will install it automatically.
These configuration specifications are defined under a file “/etc/puppet/manifests/site.pp” by default, we can split this file in to several files then include them at sites.pp.
Here is the sample site.pp file.
02 |
name => "/etc/passwd", |
10 |
package { httpd: ensure => installed } |
14 |
name => $operatingsystem ? { |
21 |
require => Package["httpd"], |
25 |
node 'puppet-client.com' { |
28 |
#All other nodes they don't have definitions associated with them will use the following node definition. |
31 |
case $operatingsystem { |
32 |
CentOS: {include apache } |
The above file is the Puppet client configuration specification written in puppet declarative language on puppet master server.
This language has a lot of constructs to define the resource and its properties.Using these constructs we manage the resources on client systems. The types of resources that puppet manages are listed bellow, plus we can add our own customized resources to mange.
Type of Resources that puppet can manage, by default:-
- Files
- Packages
- Services
- Corn Jobs
- Users and Groups
- To run Shell Commands
- And User defined resource types
Each of the above resources has a set of attributes or properties and values. Using the puppet configuration language, we can set the corresponding property values. The resource can defined by providing three main parameters: Resource type name, then inside braces({}) title of the resource and set of property values. From the above example, take the resource of type Filewith title name “password” inside that we have set of property values like name,owner,groups etc… so if a client successfully connect to server,the client puppet will apply these setting on client machine. If we change this property values, after next interval we can see the client will successfully apply it.
In this way we can control the resource configurations. On our networks there should be different types of systems (Redhat,Debian,etc..),and they have some changes in the structure of the files and other package names, so here we need to apply the configurations based on the type of clients.Puppet provide Conditional statements (if and case ) to check and apply configurations depending on client architecture. For that we need some system information from the client andfacter will provide these details. We can use that information in the puppet configuration specifications like a variable, for example: $operatingsystem (You can see all the details that facter will provide by just typing the command facter at command prompt.)
Similarly, we can specify the rules based on the client name, and using the OPPs constructs we can define the classes and reuse them with other client definitions. You can find some of them from above example site.pp file.You can do a high level configuration design using puppet language. To learn more about the language constructs, please check the puppet online wiki or a nice book which describe everything associated with Puppet by James Turnbull(Pulling Strings with Puppet.)






